


Tame Your GitHub Action Timeouts
Stick to these rules when using GitHub Actions to ensure you don’t accidentally eat up your allowance:
1. Set timeout-minutes on every single job
Always make sure your job has a sensible value set. Something slightly higher than the average run time, but don’t think just because the job is simple and “always runs in 30 seconds” you don’t need one. If you need more granular control, timeout-minutes can also be set on individual steps. Still, never omit this value on the job otherwise the default timeout of 6 hours will be used. Scripts can and will behave in unexpected ways, fail them fast.
2. Use on: push sparingly
on: push will run your workflow on every push event on every branch. Instead use
on:
push:
branches:
- develop
and set each branch explicitly. If you do need to use on: push, do so with only lightweight workflows and always set a timeout.
3. Don’t turn off your spend limit
By default, your spend limit is set to $0. Don’t touch it. If you use up all your allowance (you shouldn’t), increase it incrementally. You can always increase it more in the future.
The story of how we got here
I adore GitHub Actions.
Been playing with Github Actions this morning. Words can't explain how much better they are than every other CI I've used. 🥰
— Mark Hemmings (@mhemmings) February 5, 2020
Despite being relatively new and sparse on some advanced functionality, they’re by far the best CI experience I’ve ever had. However, they can still surprise at times, and this week they sure did.
For the last couple of months we’ve been building from scratch Ricochet’s new platform. Everything we do relies on GitHub Actions; from linting and testing on PR, to deployments with CloudFormation, to managing and rolling out DNS changes.
This week, ready for our beta launch, we’ve been rolling out our production stack. Because of that (and being bad at writing CloudFormation without a bunch of staging config hardcoded) we’ve been flying through our GitHub Action allowance. It was no surprise on Thursday when we received our first usage alert:
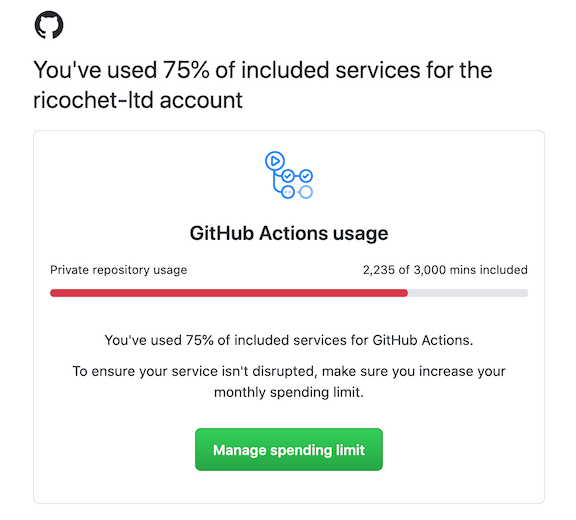
With 6 days left in our billing cycle in a month where we were running an unholy number of workflows, only having used 75% of the free allowance was a pleasant surprise. I can’t see us ever getting near the free limit again, which is impressive stuff from GitHub. Email deleted and on with my day.
That evening I came across a workflow that had failed after 45 minutes due to a bad ECS rollout. I started looking at the GitHub docs as I’d have expected a timeout before then. That’s when I came across this:
Job execution time - Each job in a workflow can run for up to 6 hours of execution time. If a job reaches this limit, the job is terminated and fails to complete. This limit does not apply to self-hosted runners.
Workflow run time - Each workflow run is limited to 72 hours. If a workflow run reaches this limit, the workflow run is cancelled. This limit also applies to self-hosted runners.
That means a single run of one badly configured workflow could theoretically cost $34.56 (72x60x$0.008). Ouch.
Sharing this with the team, we had a laugh I started adding timeouts to things in no immediate hurry.
Little did we know, the damage had already been done elsewhere.
Later that evening two more emails arrived seconds apart:

We assumed there was a delay in alerting (it does look like is some sort of delay, since these were sent at effectively the same time) and we’d used up the allowance some hours ago. We downloaded the GitHub usage report, sorted by usage, and found this:

2277 minutes (or 76% of the free allowance) had been used up that day by a single workflow. Digging around in past Action runs quickly showed the culprit. Multiple runs of a workflow had timed out after 6 hours. The thing we were laughing about earlier in the day had already stung us without us knowing.
That workflow job was a relatively simple one: on: push, startup a seeded database in Docker, and run a bunch of tests against it. The initial problem here is that it’s running on a push event to any branch. A few days ago we’d gone through all our workflows making sure that they ran in the correct things on the correct branches. This is the only one, across tens of workflows, that I’d left as a raw on:push. “It’s just tests so might as well run on all branches. What’s the worst that could happen?”. We are where we are.
I’d opened a WIP draft PR that morning for a database change I wanted to make, asking for a second pair of eyes before I went deeper into the implementation. I’d assumed what I’d done wasn’t correct; it was just 10 lines of SQL I’d typed without checking. But this was fine, being a draft PR for feedback as early as possible, we were doing things “properly”?! That SQL somehow only had a single error; a trailing comma where there shouldn’t have been one.
The workflow that runs on every push, was running. It was attempting to start the database with this new SQL and failing. Our workflow was sat waiting for a database. It waited for 6 hours. Every minor tweak I made to gather more feedback kicked off another workflow run, each one sat waiting for a database that would never appear.
By the time the broken workflows had timed out, that feature had actually been built, passed all CI runs, and made it to production. The combination of on: push, no defined timeouts, and a trailing comma ended up costing an additional $12 once we’d configured a spend limit. No real harm done, but things could’ve been much worse if we hadn’t left the spend limit at $0.
It’s a shame that workflows by default will silently take 6 hours to timeout. It would be great if GitHub decreased this to something in the range of minutes not hours, or sent an alert the first time a workflow takes >n minutes. We had however spotted some of the warning signs beforehand and not acted properly on them. From now on, all our workflows will fail as fast as they can.
Tweet